Common Types
All types referenced in this section are part of the io.cloudsoft.brooklyn.tosca13.brooklyn-tosca-core that is part of the default AMP catalog.
Root Node
The tosca.nodes.Root node is the root node type that all Node Types SHOULD derive directly (as a parent) or indirectly (as an ancestor) to promote compatibility and portability. This allows for all TOSCA nodes to have a consistent set of features for modeling and management (e.g., consistent definitions for requirements, capabilities and lifecycle interfaces). This type is useful when declaring new relationship types with targets as generics as possible.
Abstract Compute Node
The tosca.nodes.Abstract.Compute node represents an abstract compute resource without any requirements on storage or network resources.
Compute Node
The tosca.nodes.Compute node type defines a compute resource,
e.g. a VM provisioned in VMware or a cloud, or a pre-existing “BYON” (bring-your-own-node) machine.
If necessary, it is created during the create step and
can run scripts as part of the configure or start operation, as well as stop.
By default it shuts down but keeps a provisioned machine on stop
(or suspends it, for cloud machines, where shutdown is not universally available),
so that it can be restarted/resumed on a subsequent start,
and it destroys it on delete.
The following common capabilities are relevant, with limitations and/or extensions as noted:
-
host(tosca.capabilities.Compute) - as per TOSCA spec, supportingmem_size,disk_size, andnum_cpusin most environments, andcpu_frequencyandnamein some; this is not restricted to the normativevalid_source_types: [tosca.nodes.SoftwareComponent] -
os(tosca.capabilities.OperatingSystem) - not supported; the TOSCA spec is ambiguous about how to specify base images (auto-detect vs specify an image), the filtering it requires is typically not supported by cloud platforms; and the filtering is not typically powerful enough for common use cases (e.g. take the “most recent LOB-approved image with Ubuntu”); in line with the spec, this implementation expects the image/template name provided as a capability property (imageId) or as an artifact which should be passed to thecreateoperation, as described below -
endpoint(tosca.capabilities.Endpoint.Admin) - not supported -
scalable(tosca.capabilities.Scalable) - not supported, due to ambiguity; Scalability can be supported however by grouping templates using atosca.entity.DynamicClusterand attaching AMP Policies to node templates. -
binding(tosca.capabilities.network.Bindable) - not supported due to the ambiguity in the spec around re-declaring networks; many common features are available via thecloudsoftandvmwareextensions
Cloudsoft Generic Extension Capabilities
cloudsoft- the following extensions exposed by the underlying Cloudsoft AMP system are commonly used in many clouds (but not for use with VMware); see Cloudsoft / Jclouds Capabilities for more information:required.ports(java.lang.Object): Required additional ports to be applied when creating a VM, on supported clouds (either a single port as an Integer, or an Iterableor Integer[]) securityGroups(java.lang.Object): Security groups to be applied when creating a VM, on supported clouds (either a single group identifier as a String, or an Iterableor String[]) imageId(java.lang.String): A system-specific identifier for the VM image to be used when creating a VMimageNameRegex(java.lang.String): A regular expression to be compared against the ‘name’ when selecting the VM image to be used when creating a VMextraSshPublicKeyData(java.lang.String): Additional public key data to add to authorized_keys (multi-line string supported, with one key per line)installDevUrandom(java.lang.Boolean): Map /dev/random to /dev/urandom to prevent halting on insufficient entropydisableRootAndPasswordSsh(java.lang.Boolean): Whether to disable direct SSH access for root and disable password-based SSH, if creating a user with a key-based login; defaults to true (set false to leave root users alone)dontRequireTtyForSudo(java.lang.Boolean): Whether to explicitly set /etc/sudoers, so don’t need tty (will leave unchanged if ‘false’); some machines require a tty for sudo; AMP by default does not use a tty (so that it can get separate error+stdout streams); you can enable a tty as an option to every ssh command, or you can do it once and modify the machine so that a tty is not subsequently required. Usually used in conjunction with ‘dontCreateUser’ since it will prevent jclouds from overwriting /etc/sudoers and overriding the system default. When not explicitly set will be applied if ‘dontCreateUser’ is set.
VMware Capabilities
When provisioning via VSphere, the vmware capability can be used to provide extensive configuration.
The following properties are supported on this capability:
cluster(java.lang.String): The name of the ClusterComputeResource to use; if not supplied, it will auto-selectdatastore(java.lang.String): The name of the datastore to use; if not supplied, it will auto-selectresourcePool(java.lang.String): The name of the resourcePool; if not supplied, it will auto-selectcustomIpAddress(java.lang.String): IP address to request/assign for this instance; typically leave blank and have vCenter choosecustomHostname(java.lang.String): If you want to set a custom hostname otherwise leave blank and use default depending on OS, Required ifcustomHostName set.customDomain(java.lang.String): If you wish to set a custom domain otherwise leave blank and use default depending on OS. Required on linux if CUSTOM_IP setcustomSubnetMask(java.lang.String): If you wish to set a custom subnet mask otherwise leave blank and use default depending on OS. Required ifcustomHostName setcustomNameservers(java.lang.String[]): If you wish to set a custom DNS list otherwise leave blank and use default. Required if CUSTOM_IP setosFamilyOverride(org.jclouds.compute.domain.OsFamily): OS family of VMs (ignores VM metadata from VMware, and assumes this value); common values include: “windows ““linux”, “debian”, “centos”, “ubuntu”, “rhel”windowsProductId(java.lang.String): If you want to set a custom ip or hostname for a windows based machine you need to also configure the product id otherwise a default of XXXs isset which will eventually fail if not then corrected latercustomWindowsWorkgroup(java.lang.String): Set the workgroup that this server should join - defaults to WORKGROUPimageId(java.lang.String): A system-specific identifier for the VM template image to be used when creating a VMimageNameRegex(java.lang.String): A regular expression to be compared against the ‘name’ when selecting the VM template image to be used when creating a VMwindowsTimezone(java.lang.Integer): Microsoft timezone - see https://docs.microsoft.com/en-us/previous-versions/windows/embedded/ms912391(v=winembedded.11) - defaults to GMTwindowsUserOrganisation(java.lang.String): Full name of the end user. Note that this is not the username but full name specified in “Firstname Lastname” format"windowsUserFullName(java.lanf.String): Name of the organization that owns the computer.customGateways(java.lang.String[]): List of gateways to set on adapteradditionalVolumes(List<StorageVolumeDefinition>): List of maps containing keyssize(e.g."100 gb") and optionalorder(if supplied each of the n values must be unique in the range [0,n-1])managementNetworkName- the network via which AMP can access the VM under management. If this is not set then the order 0 NIC will be used.publicNetworkName- the public network. If this is not set then the management network will be used.networks(List<NetworkDefinition>): List of maps describing networks, as described below
The normative attribute sensors public_address and private_address
are set on the node entity instance,
On Windows machines, two additional sensors are available – windows.username and windows.password.encoded –
because many Windows scripts require this information (e.g. in order re-authenticate);
the latter one is base-64 encoded to prevent odd characters causing problems and casually exposing it.
VMware Networks
The NetworkDefinition object used in the networks property accepts the following fields:
- mandatory
name(the name of the network in VMware) - optional
order(as peradditionalVolumes) - optional
dhcp(described below) - optional
ipAddress - optional
subnetMask - optional
gateways(list of ip addresses, e.g.["10.0.0.1", "10.0.0.2"]) - optional
nameservers(list of ip or ipv6 addresses, e.g.["10.0.0.1", "10.0.0.2"]); on Linux these are aggregated and set globally because per-NIC DNS is not available - optional
ipV6Auto(described below) - optional
ipV6Address - optional
ipV6SubnetMask(unlike ipv4, this is the number of initial 1 bits, so64notffff:ffff:ffff:ffff::) - optional
ipV6Gateways(list of ipv6 addresses)
If the networks property is used, then the simpler customIpAddress and customSubnetMask must not be set.
Either or both IPv4 or IPv6 are supported on each network. The default is to use DHCP for IPv4
unless IPv6 is configured, where IPv6 is configured only if an explicit ipV6Address is provided
or ipV6Auto is set to auto.
The options for dhcp are as follows:
- auto: DHCP will be used to provision an IPv4 address only if nothing is specified for IPv4 or IPv6 (the default)
- enabled: DHCP will be used to provision an IPv4 address if nothing is specified for an IPv4 address
- required: provision an IPv4 address with DHCP - will fail if ipAddress or other fields are set
- disabled: DHCP is disallowed - will fail unless ipV6 is enabled or an ipAddress and other IPv4 fields are not set
The options for ipV6Autoare as follows:
- no_auto: IPv6 auto-configuration (RADVD/DHCP) will not be used; IPv6 will only be configured if an explicit ipV6Address is supplied (the default)
- auto: IPv6 is enabled and will be autoconfigured (RADVD/DHCP) if nothing is specified for an ipV6Address
- REQUIRED: IPv6 is enabled and must be provisioned automatically - will fail if ipV6Address or other fields are set
- manual: IPv6 is enabled but must be provisioned explicitly - will fail if ipV6Address is not set
- no_ipv6: IPv6 will not be configured - will fail if ipV6Address or other fields are set
In addition to the normative attribute sensors public_address and private_address,
when multiple networks are configured, additional attribute sensors are published with more information about multiple addresses.
If 2 NICs are configured then 2 extra sensors will be created as follows:
network.<network-1>.ip_addressnetwork.<network-2>.ip_address
where <network-1> and <network-2> will be replaced with the concrete names of the attached networks.
VMware Timeouts
It is recommended that VMware templates boot quickly and do not do excessive setup on first boot.
Timeouts are in place to detect and prevent errors, as shown below.
These can be overridden as vmware capability properties if required:
powerState.on.timeout: Max time to wait for power to be confirmed as on, failing if not confirmed unless ‘false’ provided here (and won’t wait), default2mpowerState.off.guestShutdown.timeout: Max time to wait for power to be confirmed as off following a guest shutdown call, failing if not confirmed unless ‘false’ provided here (and won’t wait), default10mpowerState.off.hardShutdown.timeout: Max time to wait for power to be confirmed as off following a hard power-off call, failing if not confirmed unless ‘false’ provided here (and won’t wait), default2mpowerState.off.additionalDelay: Delay between a power state off confirmation from VMware and proceeding assuming it is off (eg to deletion), because there seems to be some eventual consistency at play, default3screation.additionalDelay: Optional delay after VM created before using or performing any checks (default none; useful if other VMware checks such as CustomizationSucceeded and expected IPs report readiness too early and/or are skipped), default0guestTools.timeout: Max time to wait for VMware guest tools to be reported as operational, failing if not confirmed unless ‘false’ provided here (and won’t wait), default15mcustomizationStart.timeout: Max time to wait for VMware customization to start, skipping waiting for completion if not started unless indicated as required, default5mcustomizationStart.required: Whether to fail if customization does not start within the customizationStart.timeout period, defaultfalsecustomizationComplete.timeout: Max time to wait for VMware customization to be reported as complete, failing if not confirmed unless ‘false’ provided here (and won’t wait), default1hexpectedIps.timeout: Max time to wait for expected IPs to be reported from VMware, failing if not confirmed unless ‘false’ provided here (and won’t wait), default15m
Specifying an Image
In addition to the imageId capability property (or config on a location), which is a good
reusable way to define an image, this can be overridden on a Compute node using an artifact.
The create operation on the Standard interface can specify as its implementation primary
artifact a tosca.artifacts.Deployment.Image.VM type whose file name is taken as the
template name (in VMware) or image ID (in clouds). This will override an imageId specified
in a capability or on the location definition.
For example, with an artifact my-image defined as:
type: tosca.artifacts.Deployment.Image.VM
file: my-template
The following can be deployed to use the template/image my-template:
topology_template:
node_templates:
host:
type: tosca.nodes.Compute
interfaces:
Standard:
operations:
create: my-image
Or, if it is a one-off image and the artifact definition is being skipped,
the create line above can be replaced with:
create:
implementation:
primary:
type: tosca.artifacts.Deployment.Image.VM
file: template-installed-in-vsphere
Software Component Node
The tosca.nodes.SoftwareComponent node type is straightforward to use.
Typically, as shown in the examples, it has a host relationship to a tosca.nodes.Compute node,
and defines operations according to the tosca.interfaces.node.lifecycle.Standard lifecycle interface
(create, configure, start; stop; delete)
and tosca.interfaces.relationship.Configure interfaces on relationships
({pre,post}configure{source,target}`, as described below.
Interfaces can define and extend operations using the operation and artifact types as defined in the following section.
Host Requirement
As per the TOSCA spec, a host requirement can be supplied pointing at a Compute node.
As an extension for convenience, if a software component is defined without a host
specified, a host will automatically be created according to the default
tosca.default.location setting.
This can greatly reduce the size of blueprints in many cases,
without impacting users who wish to define hosts or define custom requirements.
As a further convenience, the capabilities used for provisioning a Compute node
can also be specified on a Software Component node.
This applies whether the host requirement is explicit or the implicit convenience is used.
In the case of RAM, disk size, and ports, the largest value is used.
In other cases it is an error if incompatible (different) values are used.
Collection Node
The brooklyn.tosca.nodes.Collection derived from tosca.nodes.Root and is a logical node which groups other nodes for lifecycle (start/stop) and management (enrichers) purposes; it has no behavior other than grouping children.
Interfaces and Operations
The tosca.interfaces.node.lifecycle.Standard lifecycle interface is the primary way that node behavior is configured:
create, configure, start; stop; delete.
In addition the tosca.interfaces.relationship.Configure interfaces on relationships ({pre,post}_configure_{source,target} allows
nodes with relationships to get additional configuration steps. (The other relationship operations,
triggered on changes, are not supported because of ambiguity in making changes.)
These are supported on most nodes, including SoftwareComponent and Compute
(with the create step of Compute extended to actually create a VM).
Standard Lifecycle - Basic Details
When a TOSCA blueprint is deployed all components declared under topology_template are created in parallel, but if dependencies are declared via relationships or TOSCA DSL functions, the process of creating pauses until the dependency is available. The node lifecycle in AMP includes the creation phases declared in TOSCA by the tosca.interfaces.node.lifecycle.Standard interface.
Three high-level effectors describe the AMP standard lifecycle. Its steps correspond to TOSCA tosca.interfaces.node.lifecycle.Standard interface’s operations as explained below:
- Start: wraps
tosca.interfaces.node.lifecycle.Standard.{create,configure,start}, waiting on dependencies, updating service sensors, and if thecheck_runningextension is enabled (recommended), confirming the service is running before completing - Stop: wraps
tosca.interfaces.node.lifecycle.Standard.stop, waiting on dependents (depending on theStopDeleteBehaviorextension) and updating service sensors - Delete: wraps
tosca.interfaces.node.lifecycle.Standard.delete, waiting on dependents (depending on theStopDeleteBehaviorextension) and updating service sensors
These high-level effectors should normally be used by operators,
as the behaviour of the low-level lifecycle.Standard operations on their own can be unintuitive.
The mapping between the AMP effectors and TOSCA Standard operations is depicted in the image below.
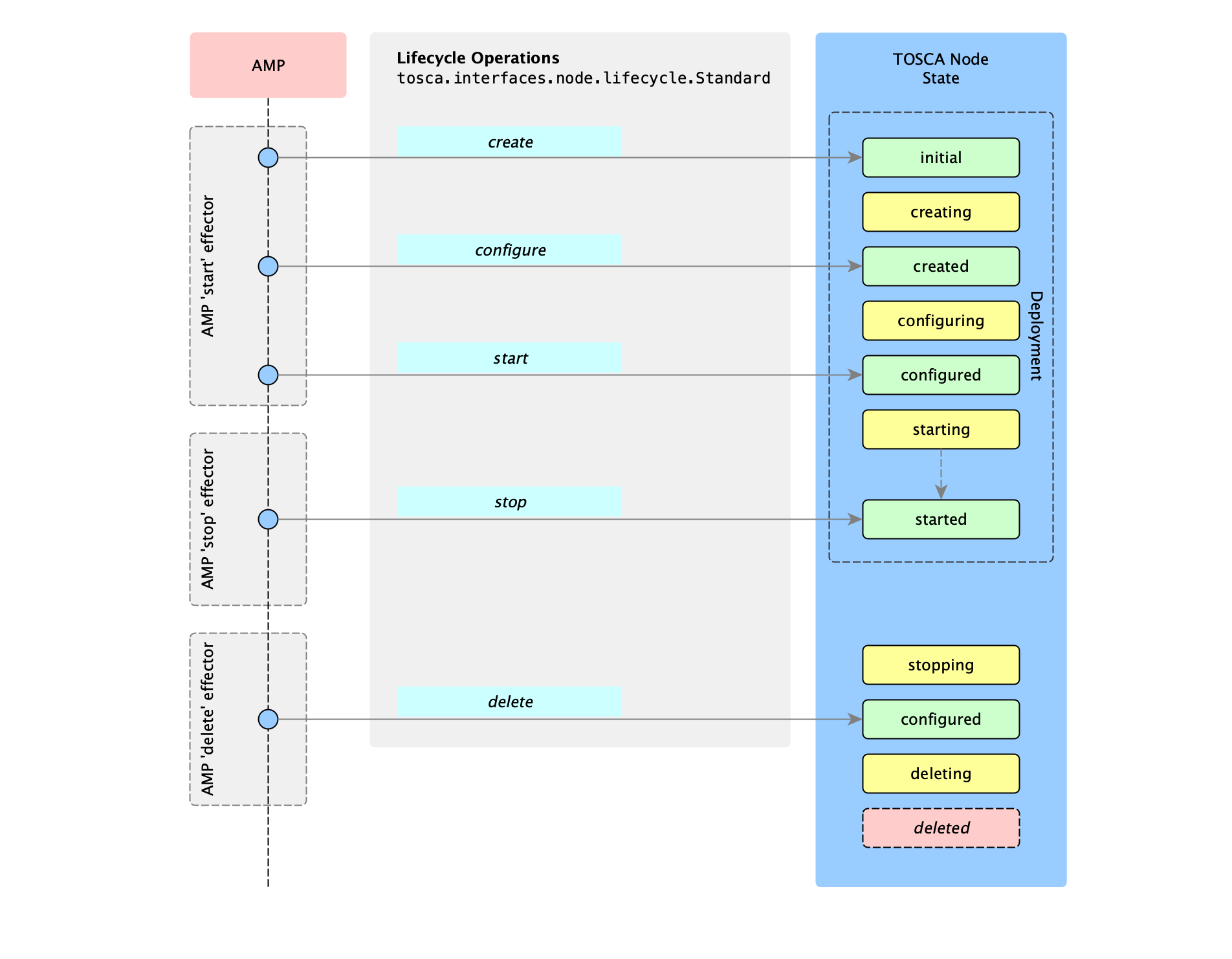
Note: deleted is not a state, it is just an abstract way of ending the transition. It represents the fact that the node managed by AMP no longer exists.
Relationship Lifecycle
The TOSCA Specification defines a set of operations for a relationship type though the tosca.interfaces.relationship.Configure interface. The list of available operations is depicted below:
- pre_configure_source
- pre_configure_target
- post_configure_source
- post_configure_target
- add_target
- add_source
- target_changed
- source_changed (mentioned once in the official TOSCA documentation)
- remove_target
- remove_source (mentioned once in the official TOSCA documentation)
AMP provides support only for the first four, which are included in the Start effector. Relationship lifecycle operations are weaved with Standard Node operations during the deployment phase.
Since the tosca.interfaces.relationship.Configure.{pre_configure_source, pre_configure_target, post_configure_source, post_configure_target} wrap the tosca.interfaces.node.lifecycle.Standard.configure node operation, these operations are mapped to the AMP Start effector.
The following image shows the approximate order of Relationship operations invocations during the deployment of an application and the correspondence to the AMP Start effector.
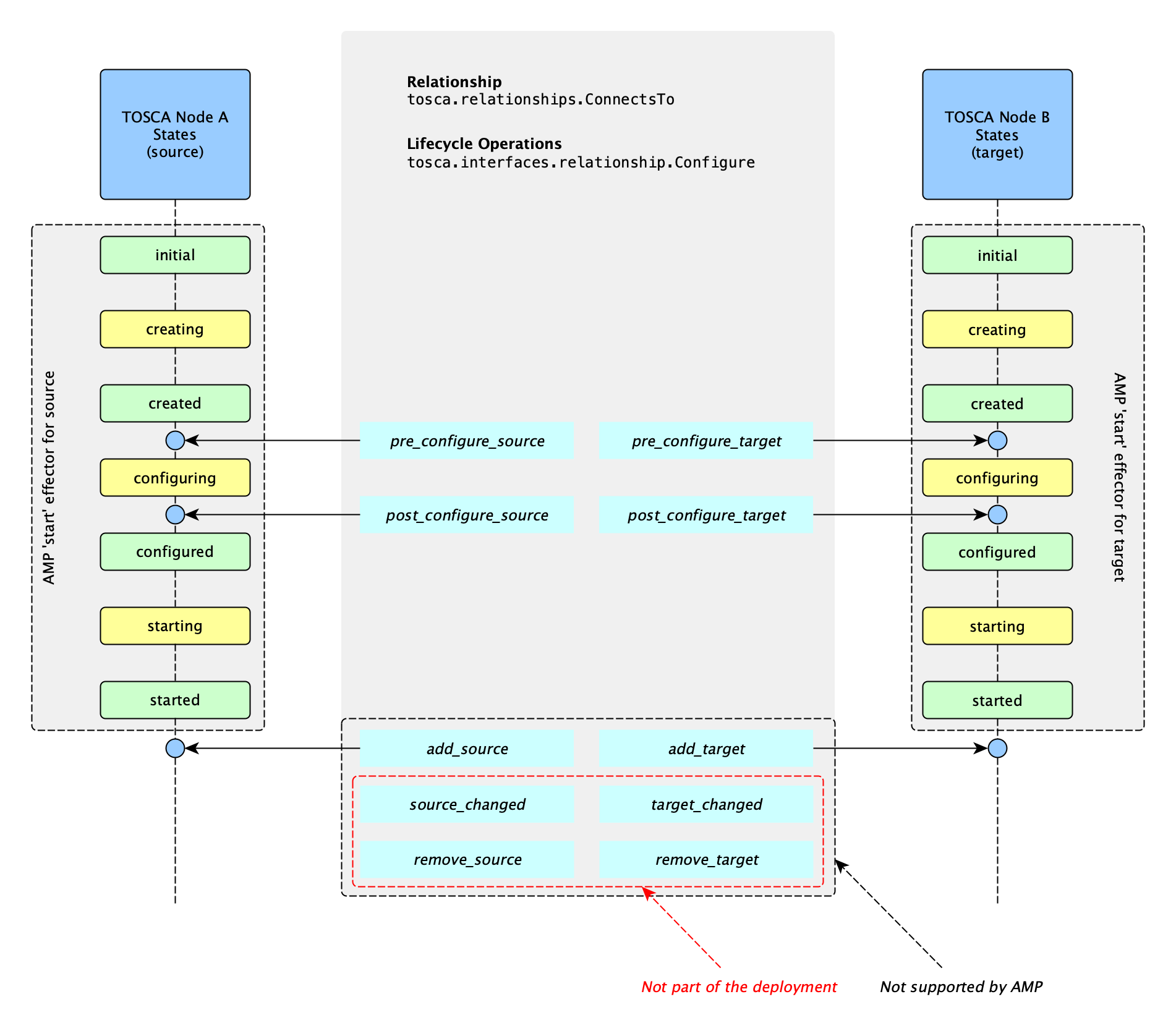
According to the official TOSCA Spec documentation, a TOSCA Orchestrator should connect a source and target node together using a relationship that supports the Configure interface by “interleaving” the operations invocations of the Configure interface with those of the node’s own Standard lifecycle interface.
The order of operations is describes in the following list, depending on which side (i.e., source or target) of a relationship a node is on:
- Invoke either the
pre_configure_sourceorpre_configure_targetoperation as supplied by the relationship on the node. - Invoke the node’s
configureoperation. - Invoke either the
post_configure_sourceorpost_configure_targetas supplied by the relationship on the node.
Note that the pre_configure_xxx and post_configure_xxx are invoked only once per node instance.
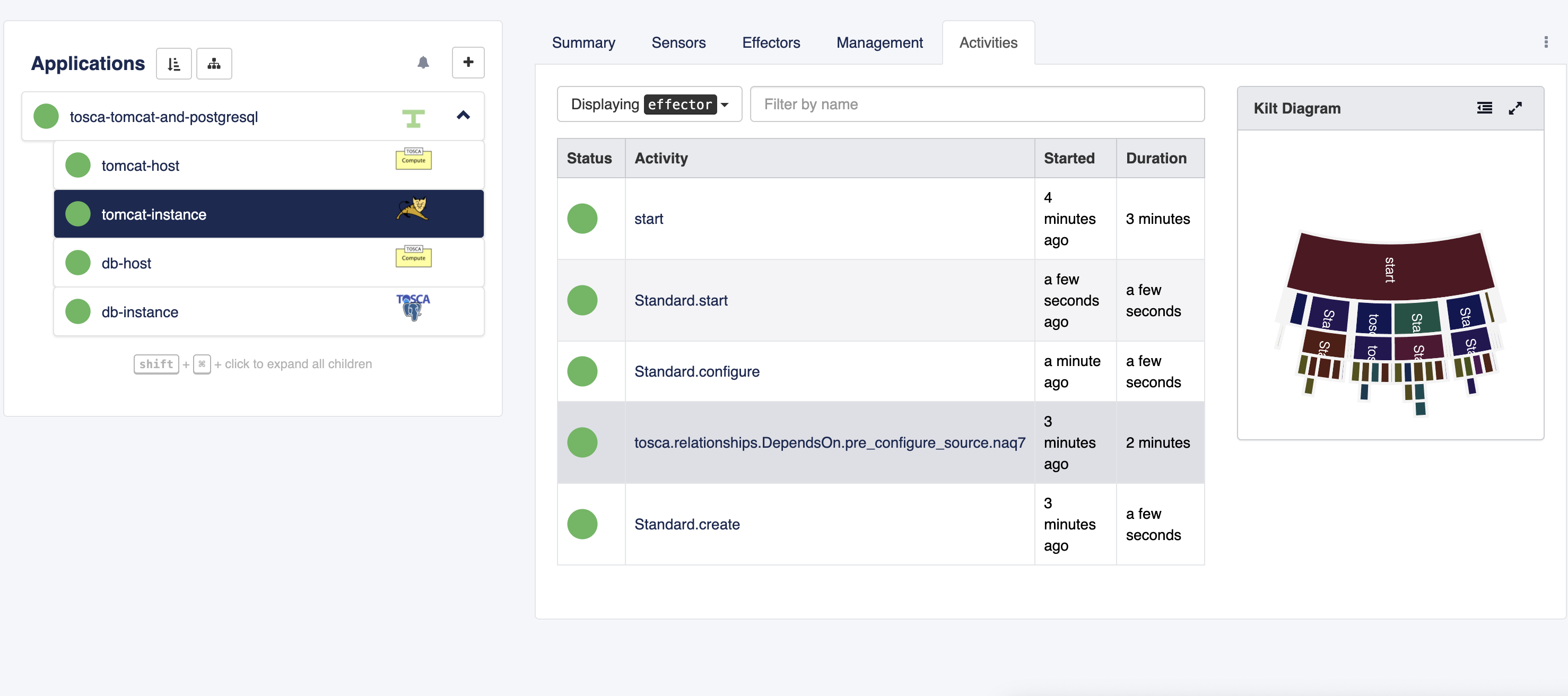
AMP displays the relationship operations in the Activities tab. The activity summary consists of the interface type and the operation name.
The following image depicts the tosca.interfaces.relationship.Configure.pre_configure_source operation shown as an activity in AMP’s inspector. The application is composed of an Apache Tomcat Node and a Database node. The Tomcat node is the source node in a DependsOn relationship, the database node is the target node.
Standard Lifecycle - Advanced details
A capability of type brooklyn.tosca.capabilities.StandardLifecycleBehavior
can be declared to configure the behavior of start / stop / delete and up-ness and heath checks,
as follows:
quorum_up: how many of a node’s children must be up for a node to report itself as up; valid values areall,atLeastOne,allAndAtLeastOne, andalwaysHealthy(no children required), or a list of numeric pairs[ [0,0],[2,2],[10,6] ]where each pair’s first co-ordinate is the number of children defined, increasing, and the second pair indicates for that number of children how many must be up, with linear interpolation (so the example requires 100% of 2 nodes, 60% of 10 nodes, explicitly, and by interpolation 67% of 6 nodes and 60% beyond 10); default isalwaysHealthyfor most nodes, so that where children are hosted on a parent the parent doesn’t also wait for children (!); however nodes which do nothing except aggregate their children can safely and usefully default toallor another quorum expression; for exampleCollection(below) defaults toall, andtopology_templateapplications also useallbehaviorquorum_healthy: how many of a node’s children must be healthy for a node to report healthy; this differs fromquorum_upin that only children which arerunningor themselves unhealthy are considered; default isallfor all nodes (options are the same asquorum_up)stop_waits_on_dependents_timeout: whetherstopshould wait for all dependencies to stop, taking either a boolean or a timeout, e.g.1hto have it wait up to one hour for dependencies to stop before deleting (default true for most node types, as e.g. shutting down aComputenode while running scripts to stop software is clearly not going to work well); note thatstopin not typically invoked on dependencies, but instead it is assumed the operator will be stopping in sequence or a parent topology will stop all nodes in parallel and this capability allows sequential resolution; also note if A depends on B and B depends on A, this behavior can cause them to block on each other, so at least one should have this capability set false if the co-dependency is correctdelete_on stop: whetherstopshould invokedelete(default false)delete_invokes_stop: whetherdeleteshouldstopthe node first (default false)delete_waits_on_dependents_timeout: whether and for how longdeleteshould wait for all dependencies to be deleted, either a boolean or a duration (defaulttruefor most node types meaning to wait indefinitely, but overridden forComputeto befalseas if you are deleting an instance there is no need normally also to delete the software on the box; can of course be overridden for specific instances or subclasses ofCompute)restart_pause: when doing arestart, how long to wait between stop completing and start being invoked; typically this should be long enough for dependent nodes to change state to prevent race conditions when restarting multiple nodes with dependencies simultaneously; default 5s
(The deprecated capability brooklyn.tosca.capabilities.StopDeleteBehavior is accepted as a synonym for this.)
The operations to start, stop, and delete are recursive;
if children nodes have the same effector, they will normally be invoked as part of the parent’s {start,stop,delete}.
Where a child does not have such an effector, behaviour will typically not recurse into children:
if combining nodes which support delete with external (non-TOSCA) nodes that do not have a delete effector,
it might be necessary to have delete_invokes_stop true.
For topology templates, the default behavior of delete is to invoke delete children which have a delete effector
and then to invoke stop on children which have a stop effector, to facilitate compatibility with nodes that do not offer delete.
Official Documentation Mentions
Note This section contains a set of details from the official OASIS TOSCA specification important when customizing interface and operations behaviour for a node.
The default sub-classing behavior for implementations of operations SHALL be overriden. That is, implementation artifacts assigned in subclasses override any defined in its parent class.
Template authors MAY provide property assignments on operation inputs on templates that do not necessarily have a property definition defined in its corresponding type.
Implementation artifact file names (e.g., script filenames) may include file directory path names that are relative to the TOSCA service template file itself when packaged within a TOSCA Cloud Service ARchive (CSAR) file.
Designers of Node or Relationship types are not required to actually provide/associate code or scripts with every operation for a given interface it supports. In these cases, orchestrators SHALL consider that a “No Operation” or “no-op”.
The default behavior when providing scripts for an operation in a sub-type (sub-class) or a template of an existing type which already has a script provided for that operation SHALL be overriden. Meaning that the subclasses’ script is used in place of the parent type’s script.
Node: Custom types mentioned in this documentation provide a good example of node types being extended to add properties and add behaviour(e.g. check out tosca-tomcat9-node that derives tosca.nodes.WebServer, and smart-tomcat9-node that derives tosca-tomcat9-node).
Node: Custom types mentioned in this documentation are designed to be used with Ubuntu 20 locations, unless a different operating system is mentioned in the template or type description.
Node Management Hierarchy
As an extension to TOSCA, building on Cloudsoft AMP management functionality, nodes can be logically grouped underneath other nodes as “parents”. This does not affect the basic start/stop functionality, but it does give several benefits:
- In the design-time blueprints in Composer and runtime models in Inspector, nodes are shown underneath their parents; this makes blueprints with many nodes easier to work with, because the groups separate different logical elements (for example different tiers)
- Invoking
start/stopon a logical parent will invoke that operation on its children, in parallel with siblings and the parent (with blocking possible where there is a dependency); this allows operations after the initial deployment to be easily carried on selected nodes as a unit - The
quorumchecks (see previous section) allow a parent node’s state to be computed based on its state and the state of its children
This logical management parenting/grouping is done using the group type brooklyn.groups.Parent
with the TOSCA group members being the intended children, and a parent property indicating
the ID of the parent node.
While any node can be a parent, the special node type brooklyn.tosca.nodes.Collection
is available to facilitate grouping without assigning any behavior to the parent other than
applying operations to its children. This is often useful for aggregated reporting and operations
without the ambiguity which can occur when the parent has additional behavior.
For example, a “host-parent” modelling approach, where a compute node is a parent of
software components hosted on it, is familiar where compute nodes are long-lasting,
but it has some limitations: there is no easy way to start the compute node without
starting the software component, and it is difficult to distinguish
a software-only error because the parent compute node will reflect the error.
An alternative “host-child” approach, where a compute node is the child of a software component
hosted on it, is not uncommon where the compute node is a comparatively unimportant facet
of the software, but again there are limitations: there is no easy way to stop the software process
without stopping the compute node.
Either of the above are acceptable, so long as the limitatons are understood;
however if all elements are wanted to be explicitly modeled, an approach where
hosts and dependents are siblings underneath a Collection is the way to go.
The template below shows the use of the Parent group and a Collection node containing sibling compute and software components:
topology_template:
node_templates:
parent-collection:
type: brooklyn.tosca.nodes.Collection
child-node1:
type: tosca.nodes.Compute
child-node2:
type: tosca.nodes.SoftwareComponent
requirements:
- host: child-node1
groups:
- parent-collection-children:
type: brooklyn.groups.Parent
members: [child-node1, child-node2]
properties:
parent: parent-collection
Operations and Artifact Types
Cloudsoft AMP supports the following artifact types within operations:
-
tosca.artifacts.Implementation.Bash: files of type*.share invoked on remote machines via SSH. If a shell script explicitly callsexit 0, the output environment variables will be unavailable. If a shell script callsexit Xm where X is not 0(ZERO) the child and the parent task fail, the deployment stops and outputs are not available. -
tosca.artifacts.Implementation.Python: files of type*.pyare invoked on remove machines via SSH, installed asmain.pyand run usingpython main.py; the OS image must have the desired version ofpythonalready installed and on the path and should support bash scripts -
brooklyn.tosca.artifacts.Implementation.WinRm.{PowerShell,Cmd,Bat}: files of type*.ps1,*.cmd, and*.batare invoked on Windows machines using WinRM; formats are preferred in that order; outputs may not be available for non-preferred formats; If a script explicitly callsExit 0theexitCodeandLASTEXITCODEoutput environment variables are available. If a shell script callsExit Xm where X is not 0(ZERO) the child and the parent task fail, the deployment stops and outputs are not available. -
brooklyn.tosca.artifacts.Implementation.WinRm.Reboot: this artifact type indicates that a windows machine should be rebooted; artifact files, dependencies, and inputs are ignored; propertiesforce(a boolean) andsleep(a duration, default0 minwhich just polls the VM) are accepted -
brooklyn.tosca.artifacts.Implementation.CredentialsUpdate: this artifact type indicates that the provided crededentials should be used for subsequent operations; artifact files, dependencies, and properties are ignored; inputslogin(string), andpassword(string) are expected. For example, when usingCredentialsUpdateas part of anInitDstatement (below), you could use the following:
01-UpdateCredentials:
implementation:
primary:
type: brooklyn.tosca.artifacts.Implementation.CredentialsUpdate
inputs:
login: { get_property: [ SELF, login_1 ]}
password: { get_property: [ SELF, password_1 ]}
-
brooklyn.tosca.artifacts.Implementation.Initd: this artifact type bundles multiple operations together in a single operation, in a propertycommandswhich takes (usually as itsdefaultvalue) a map of step IDs to an operation definition in either longhand (an operation definition map, includinginputsand animplementation) or shorthand (an artifact file or type, as a string); the step IDs are executed in alphanumeric order (the reason for this is that it allows subclasses to interleave or overwrite steps). Note that artifact files and dependencies on this artifact are ignored, but where defined on a nested operation they are respected, and outputs are taken from the last operation only. Where this artifact type is used to define an effector, an inputinput_nameto the effector can be accessed from inside the commands using the TOSCA function extension{ get_attribute: [ OPERATION, input_name ] }. -
brooklyn.tosca.artifacts.Implementation.Workflow: this artifact type allows writing Cloudsoft AMP workflows, defining at minimum the propertystepscontaining the workflow steps either in shorthand or longhand, and other properties as described in the AMP documentation for workflows. -
brooklyn.tosca.artifacts.Implementation.NoOp: indicates that the step should do nothing; although the TOSCA spec allows operations with no implementation, that can frequently be a sign of an error as use cases for no-op operations are rare; it is advised that operations should always give an implementation, and those operations which are intended to be no-op should declare this implementation artifact; in this implementation of TOSCA an error is thrown if an operation is provided without an implementation; the main use cases for this artifact are where a parent behaviour wants to be suppressed, or where an artifact is needed in conjunction withinputswhich reference aget_attributeto indicate that a step should block on an attribute being available -
tosca.artifacts.Implementation.AnsiblePlaybook: Ansible playbooks of type*.yamlare invoked via SSH on a pre-existing BYON ansible machine targeting the node that declared it. This type of artifact is peculiar because it requires a Linux machine to run Ansible commands and a target machine that is the host the playbook is run on. When the target location is Linux, Ansible uses SSH to communicate with it and run the playbook tasks. When the target location is Windows, Ansible uses WinRM. Additional specific WinRM Ansible variables can be configured in various ways, and how to do this requires its own section. The ansible machine is expected to be configured intosca.ansible.default.locationsetting which requires the public SSH key data of the ansible machine set inpublicKeyDataproperty, along withhostsanduser. (If many nodes will be connecting the ansible location, you might also want to set eithersshCacheExpiryDuration: 10sorbrooklyn.ssh.config.close: trueto prevent SSHD from throttling open sessions.) The Ansible machine is expected to haveansible-playbookinstalled with default access permissions as well assortanduniq. The artifact declaration accepts booleanbecomeproperty which is used as--becomeargument foransible-playbookif set totrue,extra_varsproperty of string type as--extra-varsargument andadditional_argumentsas a list of strings property for other arguments.Note:
additional_argumentsdoes not accept--extra-vars,--becomeor--inventoryarguments.--inventoryargument is reserved to target the node that declared this artifact, it means that inventory configured on ansible machine will be ignored.- The Ansible artifact does not prevent concurrent execution on the same target server.
Many common tasks, such as
yum installwill fail if invoked concurrently on the same machine, and some aspects of the Ansible setup performed by the orchestrator may also fail in concurrent scenarios. Where multiple Ansible installs are required on a single server, it is recommended to define a TOSCA relationship between multipleSoftwareComponenttypes, or types derived fromSoftwareComponenttype, to enforce one running after the other completes. Alternatively in some cases it may be possible to useflockorsemin your playbooks to prevent incompatible concurrent commands from running at the same time. - Masking of sensitive vars is applied to
--extra-varsonly if configured as a multi-line string:extra_vars: | password=mypassword secret=mysecretor as a map:
extra_vars: password: mypassword secret: mysecret
WinRM Ansible Variables Configurations
There are four places where WinRM Ansible configurations can be declared, and they are listed below in the order of precedence from least to greatest:
- in the configuration for the Ansible machine, in the
tosca.ansible.default.locationsetting - in the configuration of the target machine
- in the
inputssection of the interface operation - in the
propertiessection of thetosca.artifacts.Implementation.AnsiblePlaybookartifact
This section explains each of them and overriding rules.
The Ansible machine configured in tosca.ansible.default.location can declare specific WinRM Ansible configurations the target machine is a Windows instance. They can be grouped together in a map under configuration ansible_winrm like shown in example below:
brooklyn.catalog:
id: tosca.ansible.default.location
version: 1.0.0-SNAPSHOT # BROOKLYN_TOSCA13_VERSION
items:
- id: tosca.ansible.default.location
itemType: location
item:
type: localhost
brooklyn.config:
publicKeyData: ...
ansible_winrm:
port: 5985
connection_timeout: 20
transport: plaintext
Or they can be declared independently, but in this case the property names must be prefixed with ansible_winrm_.
brooklyn.catalog:
id: tosca.ansible.default.location
version: 1.0.0-SNAPSHOT # BROOKLYN_TOSCA13_VERSION
items:
- id: tosca.ansible.default.location
itemType: location
item:
type: localhost
brooklyn.config:
publicKeyData: ...
ansible_winrm_port: 5985
ansible_winrm_connection_timeout: 20
ansible_winrm_transport: plaintext
The same configuration style is supported on the target machine location configuration.
Note: WinRM Ansible configurations on the target machine location configuration override the WinRM Ansible configurations with the same name configured via the tosca.ansible.default.location.
WinRM Ansible configurations can be provided as inputs for the interface operation that uses the Ansible Playbook artifact. For practical template development, the same configuration style is supported on the target machine location configuration. So we can declare WinRM Ansible configurations as an input map:
topology_template:
node_templates:
a_server:
type: tosca.nodes.Compute
interfaces:
Standard:
configure:
inputs:
ansible_winrm:
port: 5985
connection_timeout: 20
transport: plaintext
server_cert_validation: ignore
read_timeout_sec: 30
path: /wsman
implementation:
primary:
type: tosca.artifacts.Implementation.AnsiblePlaybook
file: classpath://playbooks/winrm_playbook.yaml
Or we can declare WinRM Ansible configurations as a set of entries in the inputs map.
topology_template:
node_templates:
a_server:
type: tosca.nodes.Compute
interfaces:
Standard:
configure:
inputs:
ansible_winrm_port: 5985
ansible_winrm_connection_timeout: 20
ansible_winrm_transport: plaintext
ansible_winrm_server_cert_validation: ignore
ansible_winrm_read_timeout_sec: 30
ansible_winrm_path: /wsman
implementation:
primary:
type: tosca.artifacts.Implementation.AnsiblePlaybook
file: classpath://playbooks/winrm_playbook.yaml
The interface operation input values can be provided by TOSCA functions such as get_property or get_attribute.
Note: The WinRM Ansible configurations provided as interface operation inputs override any WinRM Ansible configurations on the target machine location with the same name. When using any transport type but certificate there are but three exceptions: ansible_winrm_host, ansible_winrm_user and ansible_winrm_password. When it comes to these three, the WinRM machine configuration is the ultimate source of truth.
WinRM Ansible configurations can also be declared as properties of a tosca.artifacts.Implementation.AnsiblePlaybook. The ansible_winrm property groups all WinRM specific configurations as shown in the example below:
node_types:
test.winrm.playbook:
derived_from: tosca.nodes.SoftwareComponent
properties:
# section omitted for brevity
interfaces:
Standard:
configure:
inputs:
ansible_winrm:
port: 8888
connection_timeout: 55
implementation: playbook
artifacts:
playbook:
type: tosca.artifacts.Implementation.AnsiblePlaybook
file: classpath://playbooks/winrm_playbook.yaml
properties:
ansible_winrm:
port: { get_property: [ SELF, winrm_port ] }
connection_timeout: { get_property: [ SELF, winrm_timeout ] }
extra_vars:
message: { get_property: [ SELF, my_parameter ] }
For practicality and readability, it is recommended to declare properties without the ansible_winrm_ prefix under the ansible_winrm key, but just to keep things going we accept properties that include the prefix too. So, the following example is considered valid.
node_types:
test.winrm.playbook:
derived_from: tosca.nodes.SoftwareComponent
properties:
# section omitted for brevity
interfaces:
Standard:
configure:
inputs:
ansible_winrm:
port: 8888
connection_timeout: 55
implementation: playbook
artifacts:
playbook:
type: tosca.artifacts.Implementation.AnsiblePlaybook
file: classpath://playbooks/winrm_playbook.yaml
properties:
ansible_winrm:
port: { get_property: [ SELF, winrm_port ] }
connection_timeout: { get_property: [ SELF, winrm_timeout ] }
ansible_winrm_transport: plaintext
extra_vars:
message: { get_property: [ SELF, my_parameter ] }
Note: The same goes for all other ansible_winrm configuration maps, from other elements introduced in this section.
Note: The WinRM Ansible configurations provided as artifact properties override any WinRM Ansible configurations declared as interface operation inputs with the same name.
Other Artifact Types
Beside the artifact types listed in the previous section the following types are also present in the catalog:
tosca.artifacts.Root- this type represents the default (root) TOSCA Artifact Type definition that all other TOSCA base Artifact Types derive from. Custom artifact types should derive from this type.tosca.artifacts.Implementationthis type represents the TOSCA Artifact Type parent type for all implementation artifacts in TOSCA. All types representing executable artifacts supported by AMP derive from this type.tosca.artifacts.File- this type represents the TOSCA Artifact Type representing a simple file. Custom files types that include additional behaviour for various types of files, should derive this type and be added to the catalog as a bundle.tosca.artifacts.Deployment- this type represents the parent type for all deployment artifacts in TOSCA. It declares no specific behaviour and is designed to be derived by custom deployment artifacts.tosca.artifacts.Deployment.Image- this type represents a parent type for any “image” which is an opaque packaging of a TOSCA Node’s deployment (whether real or virtual) whose contents are typically already installed and pre-configured (i.e., “stateful”) and prepared to be run on a known target container. In the current version of AMP, this type declares no specific behaviour and is designed to be derived by developers when creating custom image types.tosca.artifacts.Deployment.Image.VM- this type represents the parent type for all Virtual Machine (VM) image and container formatted deployment artifacts. This type is present in the AMP catalog and designed to be used as a root type when declaring derived types representing popular standard VM disk image (e.g., ISO, VMI, VMDX, QCOW2, etc.) and container (e.g., OVF, bare, etc.) formats. At the moment, AMP does not support popular standard VM disk image and container formats. However, template name (in VMware) or image ID (in clouds) can be specified. See details in Specifying an Image chapter.tosca.artifacts.template- this type represents the TOSCA base type for template type artifacts. It was added to the AMP catalog to serve as a root type for custom template type files such as CSV, XLSX, MD, ADOC, etc.tosca.artifacts.Implementation.Javais a custom artifact type representing an executable Java artifact. It can be used to configure an operation that consists of executing a class implementingio.cloudsoft.brooklyn.tosca13.ext.operations.JavaArtifactApiwithin AMP. The class must be packed in a bundle and present in the catalog.
Note: tosca.artifacts.* types that are not normative TOSCA types, but custom types provided by AMP to make creating TOSCA blueprints more practical, are aliases for types with names prefixed with brooklyn.tosca13(e.g. tosca.artifacts.Implementation.AnsiblePlaybook is an alias for brooklyn.tosca13.ExecuteAnsibleArtifact).
Repositories support
When artifacts are hosted on a secure repository (e.g. Artifactory), the repository should be declared using the repositories TOSCA configuration.
Private repositories require credentials which are provided by the credential configuration element of type tosca.datatype.Credential.
The credential configuration is not mandatory, and when its value is not set the repository is assumed to be public.
Repositories have a unique ID and are stored in the catalog. Thus, can be used in all topology_template deployed with AMP by referencing their id.
The following code snippet shows two repositories being declared and then used in a topology_template.
repositories:
cloudsoft_artifactory_repo: # private repo ID
description: Cloudsoft Artifactory Repo
url: https://artifactory.cloudsoftcorp.com/artifactory
credential:
user: xxx
token: xxx
public_maven_repo: # public repo ID
description: Public Nexus Maven Repo
url: https://repo1.maven.org/
# no credentials
# usage
topology_template:
node_templates:
example1:
type: example.CustomCompute
artifacts:
simple_script:
file: libs-release-local/io/cloudsoft/scripts/create.sh
repository: cloudsoft_artifactory_repo # private repo ID
type: tosca.artifacts.Implementation.Bash
deploy_path: /tmp/create.sh
simple_jar:
file: /maven2/junit/junit/4.13.2/junit-4.13.2.jar
repository: public_maven_repo # public repo ID
Inputs, Outputs, and Artifacts
Unless otherwise indicated, inputs are set for all artifacts,
dependencies are copied across either to the indicated deploy path or else inferred from the dependency file (URL).
Where dependencies are identified by a type name or ID in the deployment list,
an environment variable is set with the name pointing at the deployed path.
Less common and more ambiguous options, such as operation_host and timeout,
are not typically supported unless otherwise indicated for an operation.
Files in artifacts can be either URLs or absolute paths to files within the CSAR. Where node types are extended, paths within the CSAR are resolved relative first in the extension’s CSAR bundle and then to CSAR bundles where ancestors are defined. Relative paths to files within the CSAR are not supported due to ambiguity (if a node type is extended, especially in another CSAR) and because they can be brittle.
Inputs can take the TOSCA DSL (e.g. get_input, get_property, get_attribute, etc);
however shorthand and assignment syntax cannot be used with the DSL.
If using the DSL, the value must be set under the keyword default within the input.
Outputs are taken from the new environment variables that are set after execution;
for instance if a bash script does an export DATE=$(date),
an output called DATE will be available on the operation.
These are sent as “sensors” namespaced by the operation within the runtime.
The name of the interface definition (not the interface type, although
often this matches the type’s short name, e.g. Standard)
must be used when using get_operation_output.
Behaviour of artifacts on relationship operations is fully supported
with the exception that get_operation_output is not supported for the
output from relationships, for multiple reasons
(relationship templates can have multiple instances, so a reference to a relationship instance is not necessarily well-defined;
it would be well-defined for SELF except the spec says SELF is only for node templates;
and in the runtime model relationships are simpler than nodes and do not have sensors).
It is recommended that outputs be mapped to attributes on the entity,
using the syntax outputs: [ SELF, <attribute_name> ], and get_attribute: [ SELF, <attribute_name> ]
be used to access them, rather than use get_operation_output.
This is because the latter buries information which is usually important and which by definition
is needed across operations, and introduces brittleness sensitive to the interface and operation identifiers.
This implementation of TOSCA adds support for an output_defaults map where an output name and default value
can be set; these are used if the artifact does not itself produce outputs.
For usage examples and additional notes, view the Operation Examples.
On-Box Script Execution and Deletion
Scripts are executed underneath ~/.brooklyn-tosca-execution,
should for debugging purposes it be desired to access the box and inspect behaviour.
The actual structure within this is <application-id>/<entity-id>/date>-<op>/.
By default most script files, outputs, and artifacts are kept for the lifetime of a node,
and deleted automatically if and only if there is a delete command on the node.
There is an implicit property brooklyn.tosca.operations.keep_files which can be set
true to force script files to be kept, or false to force them to be deleted.
This can be set on an operation or an interface (as an input), or on a node (as a property),
with more tightly scoped settings being preferred to more generally scoped settings.
By default, most files are kept while the node is active,
with some exceptions (such as check-running, which runs very frequently),
and then deleted by the platform if and when a delete command is run.
It is normally not necessary to change this unless
commands are run frequently or the target machine is kept for a long time.
A cron job can also be set to delete old scripts if it is desired to keep them
for some other reason. The application and entity IDs are available as attributes on the node.
Checksum Validation
If a checksum value is configured for a artifact,
validation is performed on target machines when installed as part of
bash, powershell, and related operation implementations.
As per the TOSCA spec, the checksum algorithm should also be explicitly configured on any
artifact supplying a checksum, using the checksum_algorithm property.
To perform the validation, this TOSCA implementation expects a specific command on the target machines.
The command takes 3 arguments, <file> <checksum> <checksum_algorithm>.
The <file> is placed on the target machines by the operations and is guaranteed to exist,
and the <checksum> and <checksum_algorithm> arguments are exactly as supplied in the
TOSCA (case sensitive) and guaranteed by the framework to be non-blank.
The scripts themselves are typically baked in to images used with this TOSCA server.
Sample such scripts for Linux and Windows are provided below.
The script name can be configured by specifying
the keys brooklyn.tosca_verify_checksum.cmd.linux and brooklyn.tosca_verify_checksum.cmd.windows,
e.g. in the /etc/brooklyn.cfg or brooklyn.properties.
By default, on Linux it expects the script tosca_verify_checksum on the path,
and on Windows it expects the script in tosca_verify_checksum.ps1 located under C:\Scripts.
To simplify validation for the most common algorithms, this TOSCA implementation supports
some common algorithms on Linux without the above script present, using default on-box tools:
MD5, SHA1, SHA256, and SHA512 (using md5sum, sha1sum, sha256sum, and sha512sum respectively).
For other checksum algorithms the script is required, and in other cases it is often recommended, as it +
gives organizations complete control of the checksum algorithms supported depending on their requirements.
Example tosca_verify_checksum script for Linux:
#!/bin/bash
FILE="$1"
CHECKSUM="$2"
ALG="$3"
ALG_UPPER=$(echo "${ALG}" | tr '[:lower:]' '[:upper:]')
case ${ALG_UPPER} in
MD5)
COMPUTED_CHECKSUM=$(md5sum "${FILE}" | cut -d\ -f1)
;;
SHA1)
COMPUTED_CHECKSUM=$(sha1sum "${FILE}" | cut -d\ -f1)
;;
SHA256)
COMPUTED_CHECKSUM=$(sha256sum "${FILE}" | cut -d\ -f1)
;;
SHA512)
COMPUTED_CHECKSUM=$(sha512sum "${FILE}" | cut -d\ -f1)
;;
*)
echo "Unsupported checksum algorithm - ${ALG_UPPER}"
exit 1
esac
if [ "${CHECKSUM}" == "${COMPUTED_CHECKSUM}" ] ; then
exit 0
else
exit 1
fi
Example C:\Scripts\tosca_verify_checksum.ps1 script for Windows:
# C:\Scripts\tosca_verify_checksum.ps1
param(
[Parameter(Mandatory=$True, Position=0, ValueFromPipeline=$false)]
[System.String]
$artifactFile,
[Parameter(Mandatory=$False, Position=1, ValueFromPipeline=$false)]
[System.String]
$checksum,
[Parameter(Mandatory=$False, Position=2, ValueFromPipeline=$false)]
[System.String]
$algorithm
)
if(-not [string]::IsNullOrEmpty($checksum) ) {
return (Get-FileHash -Path $artifactFile -Algorithm $algorithm ).Hash -eq $checksum
}
return $False
Note: It is not necessary to support a default algorithm to this script, as this TOSCA implementation will always supply the algorithm.
Other TOSCA Catalog Types
A few TOSCA normative types have been mapped to existing AMP types or limited implementations have been added to the catalog.
TOSCA Normative Node Types
The following TOSCA Normative Node Types are supported:
tosca.nodes.Root- the TOSCA Node Type all other TOSCA base Node Types derive from.tosca.nodes.Abstract.Compute- represents an abstract compute resource without any requirements on storage or network resources.tosca.nodes.Compute- one or more real or virtual processors of software applications or services along with other essential local resources. The resources the compute node represents can logically be viewed as a (real or virtual) “server”.tosca.nodes.SoftwareComponent- represents a generic software component that can be managed and run by a TOSCA Compute Node Type.tosca.nodes.WebServer- represents an abstract software component or service that is capable of hosting and providing management operations for one or more WebApplication nodes. In AMP this is an alias for aSoftwareComponentto allow flexible configurations. Derive this type when creating concrete web server node types, to underline the scope of the node type being declared.tosca.nodes.WebApplication- represents a software application that can be managed and run by a TOSCAWebServernode. In the current version of AMP there is no general use case that requires customization, so this type was added to the catalog to allow developers to scope their own types by deriving from this type.
Note: In AMP the tosca.capabilities.Endpoint is currently not supported.
tosca.nodes.DBMS- represents a typical relational, SQL Database Management System software component or service.tosca.nodes.Database- represents a logical database that can be managed and hosted by a TOSCADBMSnode. In the current version of AMP this type declares parameter to customize a logical database such as: logical name, database port, database user and password.tosca.nodes.Abstract.Storage- represents an abstract storage resource without any requirements on compute or network resources.tosca.nodes.Storage.ObjectStorage- represents storage that provides the ability to store data as objects (or BLOBs of data) without consideration for the underlying filesystem or devices. In AMP thetosca.capabilities.Endpointis currently not supported.tosca.nodes.Storage.BlockStorage- represents storage that provides the ability to store data as objects (or BLOBs of data) without consideration for the underlying filesystem or devices.
Note: In AMP the tosca.capabilities.Attachment is currently not supported.
tosca.nodes.Container.Runtime- represents operating system-level virtualization technology used to run multiple application services on a singleComputehost. In AMP this is an alias for aSoftwareComponentto allow flexible configurations.tosca.nodes.Container.Application- represents an application that requires Container-level virtualization technology.tosca.nodes.LoadBalancer- represents logical function that be used in conjunction with a Floating Address to distribute an application’s traffic (load) across a number of instances of the application (e.g., for a clustered or scaled application).
TOSCA Capabilities Types
tosca.capabilities.Root- this is the default (root) TOSCA Capability Type definition that all other TOSCA Capability Types derive fromtosca.capabilities.Node- derived fromtosca.capabilities.Rootand represents the base capabilities of a TOSCA Node Typetosca.capabilities.Container- derived fromtosca.capabilities.Rootand when declaring a node type (or a template definition), if a capability of this type is included it indicates that the node can act as a container for (or a host for) one or more other declared Node Types.tosca.capabilities.Compute- derived fromtosca.capabilities.Container. When declaring a node type, if a capability of this type is included it indicates that the node can provide hosting on a named compute resourcetosca.capabilities.Network- derived fromtosca.capabilities.Rootand when declaring a node type (or a template definition) it indicates that the node can provide addressiblity for the resource a named network with the specified portstosca.capabilities.Storage- derived fromtosca.capabilities.Rootand when declaring a node type (or a template definition) it indicates that the node can provide a named storage location with specified size rangetosca.capabilities.Attachment- derived fromtosca.capabilities.Root, but it does not declare any additional properties of behaviour in AMP (limited support)tosca.capabilities.Endpoint- derived fromtosca.capabilities.Rootand should be used or extended to define a network endpoint capability. In AMP, it includes all properties in the specification. There is no clear use case for this type in AMP since network information is provided using custom capabilities such asvmwareand location definitionstosca.capabilities.OperatingSystem- derived fromtosca.capabilities.Rootand should be used to express an Operating System capability for a node. Although present in the catalog, this type is not really used, because of the existence of locationstosca.capabilities.Scalable- derived fromtosca.capabilities.Rootand should be used to express a scalability capability for a node. Although present in the catalog, this type is not really used, because of the existence of entities such as DynamicCluster and the AMP AutoScaling policybrooklyn.tosca.capabilities.StopDeleteBehavior- derived fromtosca.capabilities.Root, it is a custom AMP TOSCA type that can customize the behaviour of nodes in a relationship at delete time. Note: This capability is now deprecated, since the customization of the delete behaviour now can be donw when triggering thedeleteeffector
TOSCA Normative Interface Types
tosca.interfaces.Root- this is the default (root) TOSCA Interface Type definition that all other TOSCA Interface Types derive from. Custom type of interfaces added to the catalog must derife from this type.tosca.interfaces.node.lifecycle.Standard- this is the core TOSCA Interface type declaring the five normative node lifecycle operations:create,customize,start,stopanddelete. Interface templates of this type can provide custom implementations for the operation. When deriving this type additional operations can be added and in AMP, they will become available as effectors. The additional operations are not part of the lifecycle, and they can only be triggered manually or using AMP Policies.tosca.interfaces.relationship.Configure- this is the core TOSCA Interface type declaring the normative relationship lifecycle operations. For lack of use cases, support is limited in the current version of AMP.
TOSCA Normative Relationship Types
tosca.relationships.ConnectsTo- this is the type that represents a network connection relationship between two nodes. Since AMP makes use of various node capabilities to establish networks and connect nodes to each other, currently there is no real use-ces for this type. The type currently present in the catalog has no behaviour attached, but types and be derived from it and behaviour can be attached to the few relationship lifecycle phases currently supported.tosca.relationships.HostedOn- this is the most important relationship type and represents a hosting relationship between two nodes. The implementation in the current version of AMP supports declaring a host for another node that AMP will identify at deploy time via the provided id.tosca.relationships.DependsOn- this type represents a general dependency relationship between two nodes. Since dependency between two nodes can be configured using TOSCA DSL functions, there is no real use-case for this type. It can be derived and behaviour can be attached to the few relationship lifecycle phases currently supported.tosca.relationships.AttachesTo- this type represents an attachment relationship between two nodes. The TOSCA specification is unclear about what kind of behaviour is required for this relationship, so this type was added to the catalog without any behaviour and developers can choose to derive it to create new types and attach custom behaviour.tosca.relationships.RoutesTo- this type represents an intentional network routing between two Endpoints in different networks. Since the current version of AMP does not supporttosca.capabilities.Endpoint, an empty version of this type was added to the catalog to allow custom derivation by developer.
Note: Future versions of AMP might add more behaviour to these types based on real use-case scenarios and recommendations from users.
TOSCA Policy Types
The current version of the TOSCA official documentation is scarce in details in regards to policy types. There are a few types described in the documentation but the policy behaviour is unclear. A single match could be made between the TOSCA tosca.policies.Scaling policy type and the Cloudsoft AMP org.apache.brooklyn.policy.autoscaling.AutoScalerPolicy. More information about using this policy can be found in the Additional Topics section.
The tosca.policies.Root is part of th catalog to provide developers a root type for custom policies added to the catalog.
Cloudsoft AMP and Cloudsoft AMP Types
Existing Cloudsoft AMP SoftwareProcess types follow a different lifecycle and location model to TOSCA; however they can easily be used from within TOSCA
by wrapping it in the special type brooklyn.tosca.entity.SoftwareProcessWrapper (which extends tosca.nodes.SoftwareComponent).
This will ensure it gets the TOSCA location information, whether from requirements or an implicit tosca.default.location,
and that TOSCA lifecycle methods and attributes are exposed by SoftwareProcessWrapper while the wrapped AMP SoftwareProcess
can follows its semantics.
This can be done as follows(shown for the simple EmptySoftwareProcess, but of course this works for Ansible, Chef, Terraform, and other popular Cloudsoft AMP entities):
topology_template:
node_templates:
a_software:
type: brooklyn.tosca.entity.SoftwareProcessWrapper
properties:
wrapped_spec:
$brooklyn:entitySpec:
type: org.apache.brooklyn.entity.software.base.EmptySoftwareProcess
AMP Enrichers, Policies and Initializers can be attached to node and topology templates using TOSCA groups.
The group used to attach these could be named appropriately, (add_brooklyn_types as shown in the next code YAML sample) and it has to be of type brooklyn.tosca.groups.initializer.
The various AMP types are provided as a list, grouped based on their type, as a valued to properties of this type.
tosca_definitions_version: tosca_simple_yaml_1_3
metadata:
template_name: sample-template
topology_template:
node_templates:
sample-node:
type: tosca.nodes.Compute
groups:
- add_brooklyn_types:
members: [ < sample-node <or list or memebers> or sample-template>]
type: brooklyn.tosca.groups.initializer
properties:
brooklyn.initializers: <list of AMP Initializers here>
brooklyn.policies: <list of AMP Policies here>
brooklyn.enrichers: <list of AMP Enrichers here>
TOSCA does not have a definition for a location type. Thus, AMP locations can be used in TOSCA templates, by using groups as well.
A location can be set to a node or a topology template; when applied to a topology template, all node templates will be associated with that location.
The brooklyn.tosca.groups.initializer is used to attach a location as well as shown in the following example:
tosca_definitions_version: tosca_simple_yaml_1_3
metadata:
template_name: sample-template
topology_template:
node_templates:
sample-node:
type: tosca.nodes.Compute
groups:
- add_brooklyn_types:
members: [ < sample-node <or list or memebers> or sample-template>]
type: brooklyn.tosca.groups.initializer
properties:
location:
- <locationID>
Re-use of Templates as Node Types
AMP allows for a topology template to be used as a type for node template. This promotes reusability.
TOSCA Data Types
There are a few TOSCA types declared in the catalog, that can be used as types for properties/inputs/attributes and as bases to declare other custom types. Some of them are TOSCA normative datatypes, some of them are internal AMP types used to support them.
bean-with-typeandtosca-data-type-definitionare the base types for providing support of TOSCA normative datatypesrange- models the TOSCArangetype (Section 3.3.3, TOSCA documentation reference) using theorg.apache.brooklyn.util.core.units.RangeCloudsoft AMP type.scalar-unit.time- models the TOSCAscalar-unit.timetype (Section 3.3.6.5, TOSCA documentation reference) using theorg.apache.brooklyn.util.time.DurationCloudsoft AMP type.scalar-unit.size- models the TOSCAscalar-unit.sizetype (Section 3.3.6.4, TOSCA documentation reference) using theorg.apache.brooklyn.util.core.units.ByteSizeCloudsoft AMP type.scalar-unit.frequency- models the TOSCAscalar-unit.frequencytype (Section 3.3.6.6, TOSCA documentation reference) using theorg.apache.brooklyn.util.core.units.FrequencyCloudsoft AMP type.brooklyn.tosca.scalar-unit.time_or_boolean(alias for:org.apache.brooklyn.util.core.units.DurationOrBoolean)tosca.datatypes.json(alias:json) - models the TOSCA type with the same name, validations using theschemaconstraint are not supportedtosca.datatypes.xml(alias:xml) - models the TOSCA type with the same name, validations using theschemaconstraint are not supportedtosca.datatypes.Credential(alias:Credential,io.cloudsoft.brooklyn.tosca13.model.ToscaCredential) - models the TOSCA type with the same name and relies on a Java implementation. The TOSCA properties declared for the type are for reference only; since are defined in the java class instead.tosca.datatypes.Repository(alias:Repository,io.cloudsoft.brooklyn.tosca13.model.ToscaRepository) - models the TOSCA type with the same name and relies on a Java implementation. The TOSCA properties declared for the type are for reference only; since are defined in the java class instead.tosca.datatypes.TimeInterval(alias:TimeInterval) - models the TOSCA type with the same nametosca.datatypes.network.NetworkInfo(alias:NetworkInfo) - models the TOSCA type with the same nametosca.datatypes.network.PortInfo(alias:PortInfo) - models the TOSCA type with the same nametosca.datatypes.network.PortDef(alias:PortDef) - models the TOSCA type with the same nametosca.datatypes.network.PortSpec(alias:PortSpec) - models the TOSCA type with the same name
AMP Support Types
TOSCA concepts are supported by the Cloudsoft AMP orchestrator using custom internal types that are visible in the catalog. These types should not be used when writing TOSCA Blueprints, but they can be extended and used in custom Java types declared within a bundle. This section lists these types and their purpose:
brooklyn.tosca.application- type used to mark an application build using a TOSCA blueprint as a TOSCA application. This adds thedeleteeffector to the list of effectors supported by the deployed application.add.tosca.attribute- type used to provide support for TOSCA attributes. Under the bonnet this type is responsible for converting attribute declarations into sensors used by AMP to display data exposed by a running entity.add.tosca.interface- type used to provide support for TOSCA interfaces. Under the bonnet this type is responsible for converting interface declarations into effectors.add.tosca.output- type used to provide support for TOSCA interfaces. Under the bonnet this type is responsible for converting outputs declarations into sensors.add.tosca.requirement.definitionandadd.tosca.requirement.assignment- types are used to provide support for TOSCA requirements. Under the bonnet these types are responsible for requirements being declared, assigned and validated.brooklyn.tosca.ToscaEntityFinder- type used to search for and retrieve TOSCA nodes/interface templates using their TOSCA identifier as a criteria.brooklyn.tosca.ToscaDslFunctions.join- type used to provide thejoinfunction implementation for the TOSCAjoinDSL functionbrooklyn.tosca.ToscaDslFunctions.token- type used to provide thetokenfunction implementation for the TOSCAtokenDSL functiontosca.entity.DynamicCluster- a custom TOSCA AMP type that takes a topology template as an argument which is used to create a cluster of notes of that type.brooklyn.tosca.entity.SoftwareProcessWrapper- AMP custom TOSCA type that creates aSoftwareComponentnode that does not require a host, because a host for it, is created by default.tosca.javatypes.PersistenceMigrator- a custom AMP type, implementingio.cloudsoft.brooklyn.tosca13.ext.operations.JavaArtifactApi. A custom interface operation can be declared using an executable artifact of this type, to add an effector to the application that can be invoked to trigger a persistence migration operation.