Run AMP in high-availability mode
Objectives
At the end of this lesson you will:
- Understand configuring AMP for high availability
- Have tested AMP failing over to a secondary instance
Pre-requisites
This tutorial assumes you have two VMs with AMP already installed. If this is not the case, please refer to tutorial 1.
Instructions
Running AMP with High Availability
This tutorial describes how to run AMP in a simple 2-node high availabilty configuration. Further information on configuring high availabilty can be found in the high availability documentation.
In order to run in high-availability mode, two or more AMP servers must have access to a shared
data store. Details of supported data stores is in the
operations persistence guide. Here, we’ll use AWS S3
and will configure AMP with the access details. This configuration will be needed for all nodes
participating in the HA cluster. In the file brooklyn.cfg, add the lines
below (substituting your AWS access key):
brooklyn.location.named.aws-s3-eu-west-1=aws-s3:eu-west-1
brooklyn.location.named.aws-s3-eu-west-1.identity=<AWS Identity>
brooklyn.location.named.aws-s3-eu-west-1.credential=<AWS Credential>The configuration options to launch AMP in high-availability mode can be found in the
org.apache.brooklyn.osgilauncher.cfg file. By default the high-availability options are disabled and
commented-out in the configuration file. To enable them, set the following options:
highAvailabilityMode=AUTO
persistMode=AUTO
persistenceLocation=aws-s3-eu-west-1
persistenceDir=my-s3-bucket-nameThe options used are as follows:
highAvailabilityMode=AUTO: AMP will look for other management nodes and allocate itself as master or standby (see HA Options)persistMode=AUTO: AMP will rebind to existing state, or start up fresh if no state is available (see Persist Options)persistenceLocation=: This is the location which AMP will use for persisted data. This should match the location defined in the server’sbrooklyn.propertiesfilepersistenceDir=: For S3-backed persistence, this is the name of the S3 bucket to be used for the persistence files. NOTE: in S3, bucket names are globally unique and you must choose a unique name
HA Options
The high availability mode is configured by setting the ‘highAvailabilityMode’ setting. Possible values are:
DISABLED: management node works in isolation - will not cooperate with any other standby/master nodes in management planeAUTO: will look for other management nodes, and will allocate itself as standby or master based on other nodes’ statesMASTER: will startup as master - if there is already a master then fails immediatelySTANDBY: will start up as lukewarm standby with no state - if there is not already a master then fails immediately, and if there is a master which subsequently fails, this node can promote itselfHOT_STANDBY: will start up as hot standby in read-only mode - if there is not already a master then fails immediately, and if there is a master which subsequently fails, this node can promote itselfHOT_BACKUP: will start up as hot backup in read-only mode - no master is required, and this node will not become a master
Persist Options
The persistence mode. Possible values are:
DISABLED: will not read or persist any stateAUTO: will rebind to any existing state, or start up fresh if no stateREBIND: will rebind to the existing state, or fail if no state availableCLEAN: will start up fresh (removing any existing state)
Once you have configured the location in the brooklyn.cfg file and the high-availability options in org.apache.brooklyn.osgilauncher.cfg, you can launch AMP on the first server with the following command:
#(CentOS / RHEL)
systemctl start amp
#(Ubuntu / Debian / Vagrant)
start amp
#(OSX / DIY)
./bin/start ampOnce AMP has launched on the first server, you can launch the second server using the same command.
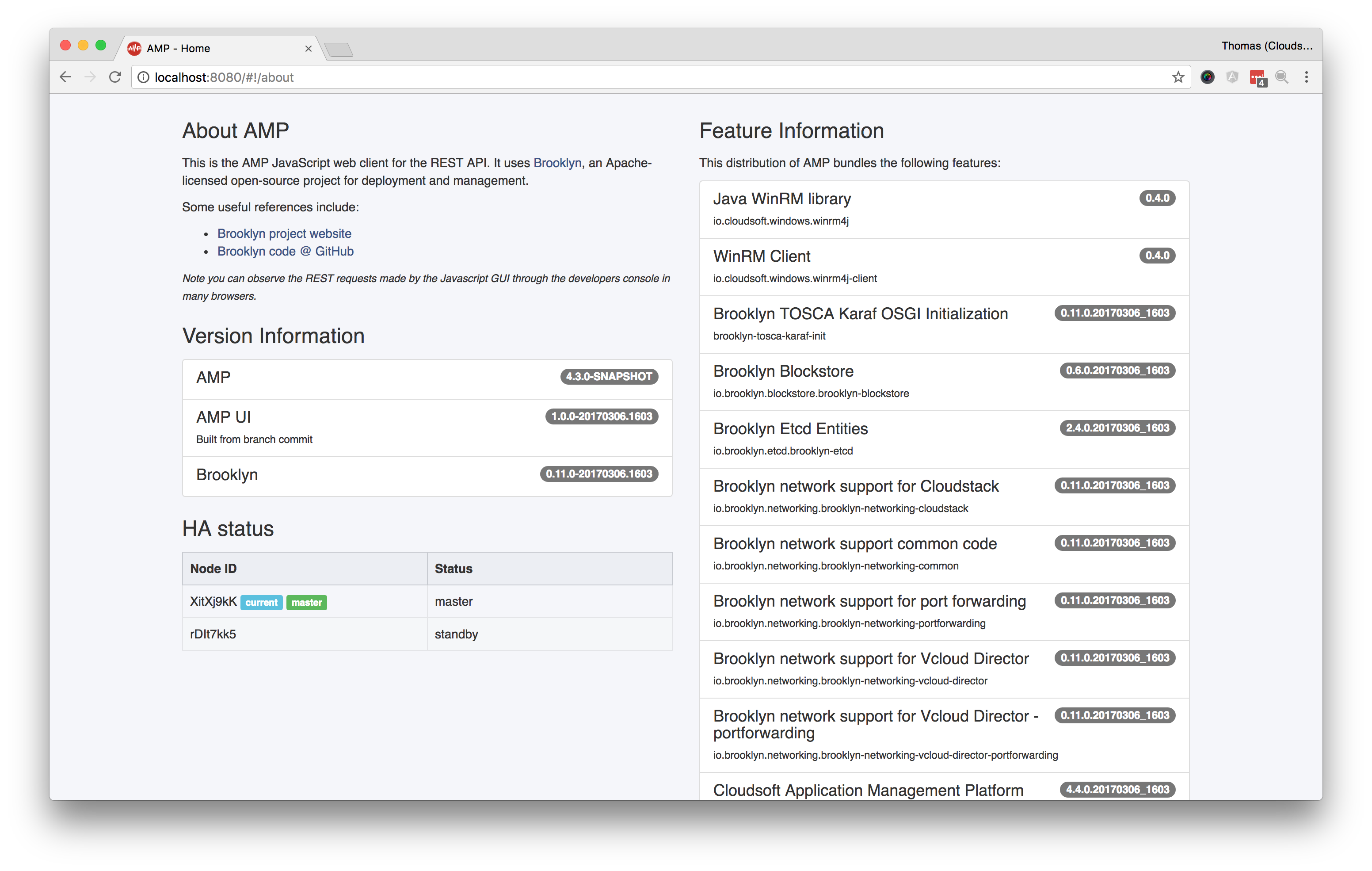
Viewing the High Availability Status
You can see the high-availability status of each AMP node, in the web console of the master AMP server by going to the about page in the home module. If you attempt to access the console of the second AMP server, you will instead see a warning that the server is not the high availability master.
To query the high-availability state of a running AMP server, one can use the curl command below:
curl -k -u myusername:mypassword http://<ip-address>:8081/v1/server/ha/state Testing Failover
To test failover, stop the master node using the bin/stop script, which will stop AMP on the first server and update
its persisted state to indicate that it is stopped. The second AMP server will immediately be promoted to master
and will continue to manage any deployed entities. It will now be available via the web console
If the first server is unable to update its persisted state to indicate that it has stopped, e.g. in the event of a
machine failure, the second node will automatically take over when the master node fails to write heartbeat events
to the persisted state. The default failover period in the absence of a heartbeat is thirty seconds. It is possible to
simulate this type of failover by killing the AMP process on the master node using a kill -9.
Summary
This tutorial has demonstrated AMP’s support for High Availability.
Next
- Explore more Tutorials